docs.anthropic.com
Explore the context window - Claude Code Docs
An interactive simulation of how Claude Code's context window fills during a session. See what loads automatically, what each file read costs, and when rules and hooks fire.
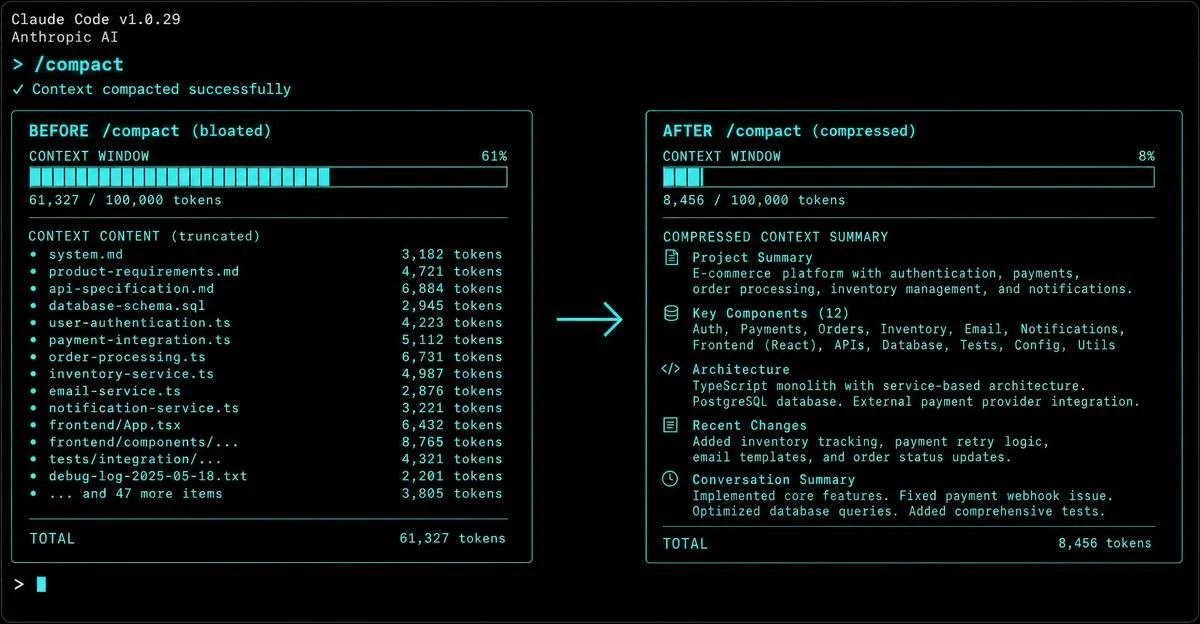
上下文窗口膨胀是 Claude Code 工作质量下滑的主要原因之一。本文完整拆解 /compact、/clear、/context 三个命令的机制差异:/compact 压缩历史并重新注入 CLAUDE.md,/clear 干净切换任务,/context 诊断膨胀来源。附带带引导指令的压缩模板、任务切换决策表和配合日常节奏的维护节奏建议。

/compact、/clear、/context 三个命令各自做什么、什么时候用哪一个,以及怎么配合日常工作节奏形成一套可持续的维护习惯。paths: frontmatter 触发后加载的)/context。/context 比等到撑满才反应要经济很多 2。/cost(/usage 的别名)可以配合 /context 一起用——前者看当前会话的 token 消耗和费用,后者看上下文在哪儿膨胀。/compact 的工作机制是把当前会话的对话历史概括成一份结构化摘要,替换原有的历史内容,然后继续同一个会话 3。| 机制 | /compact 之后 |
|---|---|
| 系统提示词和 Output Style | 不变,不属于消息历史 |
| 项目根目录的 CLAUDE.md 和无 paths 前置的规则 | 从磁盘重新注入 |
| Auto memory | 从磁盘重新注入 |
| 已调用的 Skill 正文 | 重新注入,单个 Skill 上限 5000 token,总上限 25000 token |
带 paths: 的条件规则 | 丢失,下次读到匹配文件时才重新加载 |
| 子目录里的嵌套 CLAUDE.md | 丢失,下次读到该子目录文件时重新加载 |
/compact 不带任何参数,模型会自行决定保留什么——长会话里这很容易丢掉你之后还需要的关键决策。在 /compact 后面加一两句说明,指定要保留的架构决策、文件路径或设计选择,效果明显更好:/compact Preserve the auth refactor decisions: we chose JWT with
rotating refresh tokens, token service is in src/lib/auth/tokens.ts,
migration adds a refresh_tokens table./compact We're moving to phase 2. Preserve the route structure decisions
(REST for CRUD, webhooks for async events) and the middleware chain order.
Drop the TypeScript config debugging./clear 不是放弃——跑 claude -c 随时可以回到最近一个会话,claude --resume 加名字或 ID 可以回到任意历史会话。可以把 /clear 理解成「下班打卡」,而不是「删档」。| 场景 | 用法 |
|---|---|
| 任务进行中,上下文低于 60%,工作还在继续 | 不操作,继续 |
| 到了一个阶段性节点,需要保留架构决策但不需要逐步实现细节 | /compact + 引导指令 |
| 切换到完全不相关的任务 | /clear |
| 模型开始重复或出错,会话已多次压缩 | /clear |
| 需要换 MCP 服务器、换分支或开 git worktree | 开新会话 |
/btw。它允许你在不把内容写进对话历史的情况下问一个问题——用于临时查一个无关的事,不想让这次对话污染当前会话的上下文。/context,确认上下文占用在合理范围内。如果发现有某个 MCP 工具或大文件在持续占用但没在用,及时清理。/compact + 引导指令压缩,把当前阶段的关键决策点名列出。类似做一次会议纪要——不是写进文件,而是告诉 Claude 摘要时要保留什么。/clear。如果两个任务有上下文关联(比如先做了 schema 设计,现在要按设计实现),保留会话更好;如果完全独立,/clear 后重新开始通常更干净。/clear 前先让 Claude 生成一份「handoff 文档」——用一段提示让它把当前状态、未完成的事项和关键决策汇总一遍,输出到文件,然后再 /clear。这样新会话开始时把这份文档 @ 进来,连贯性不会断 5。/compact 是免疫的——即便把对话历史压缩掉,项目规则、架构约定、常用命令都还在 1。An interactive simulation of how Claude Code's context window fills during a session. See what loads automatically, what each file read costs, and when rules and hooks fire.
Complete reference for commands available in Claude Code, including /compact, /clear, /context, and all other built-in commands and bundled skills.

Practical tips for getting the most from Claude Opus 4.7's 1M context window in Claude Code. Effort levels, proactive compaction, subagent delegation, and more.
このコンテンツについて、さらに観点や背景を補足しましょう。