GitHub Trending Top 10: Code knowledge graphs arrive (May 18–25)
This week's top 10 GitHub Trending repos introduce a new sub-category — pre-indexed code knowledge graphs — with CodeGraph (+18K stars) and Understand-Anything (+9K stars) taking different angles on the same problem. The agent skills pattern expands into academic research (ARS, +11K) and the CLI layer (CLI-Anything). Plus: a 205K-star coding workflow framework, a local-first desktop agent, a free AI engineering curriculum, WiFi-based spatial sensing, on-device TTS, and a Raspberry Pi coding agent. All 10 entries include problem / stack / differentiation / verdict.

This week's chart reads differently from last week's. The agent infrastructure theme continues, but a new sub-category surfaced explicitly: pre-indexed code knowledge graphs, with two independent implementations landing in the top five simultaneously. Meanwhile, the agent skills pattern — SKILL.md files that give coding agents behavioral instructions — expanded beyond software engineering into academic research and scientific tooling. Two hardware-adjacent repos break the all-software pattern: one turns WiFi signals into spatial sensing data, the other runs a 99-parameter TTS model fast enough to run on a Raspberry Pi.
Entries below are ranked by weekly star gain for the May 18–25 window.
#1 · colbymchenry/codegraph — 22,000 stars · +18,136 this week
Problem solved: Every time an AI coding agent starts a task, it re-discovers the codebase from scratch — grep, read, repeat. On large repos, this wastes tokens and time on work that is structurally identical across sessions. CodeGraph pre-indexes the codebase into a local SQLite database and exposes it through a Model Context Protocol (MCP) server with 9 query tools, so agents query the index rather than re-crawling files. 1
Stack and approach: TypeScript, built on tree-sitter for deterministic parsing across 19+ languages. The index stores symbols, call graphs, and framework-aware route resolution for 14 frameworks (Express, Django, Rails, Spring, SvelteKit, and more) in SQLite with FTS5 full-text search. Ships as a self-contained Node.js binary — no native build step required. File watchers (FSEvents/inotify/ReadDirectoryChangesW) keep the index current with a 2-second debounce. Supports Claude Code, Cursor, Codex CLI, OpenCode, and Hermes. 1
Differentiation: CodeGraph's published benchmarks (v0.9.4, 7 real-world repos including VS Code, Django, and Tokio) report a median of 35% cost reduction, 57% fewer tokens, 46% faster task completion, and 71% fewer tool calls compared to native agent exploration. 1 The Swift Compiler repo (25,874 files) indexed in under 4 minutes; a complex cross-file question resolved in 35 seconds with zero file reads. 1 Community skepticism exists — some Reddit users have called pre-indexed KG tools "placebo/hype" — but CodeGraph's methodology is specific enough to examine: 7 repos, 4 runs per arm, raw data provided. 2 Shubham Choudhary at Towards AI observed that the tool "solves a very real problem: AI agents waste too much time exploring codebases through repeated file search." 3
Verdict: ⭐ Star it. The benchmark methodology is transparent and the zero-config install path is friction-free. Run it on a real project before committing — but the numbers are concrete enough to take seriously.
#2 · tinyhumansai/openhuman — 27,200 stars · +15,194 this week
Problem solved: Most AI agents reset between sessions. OpenHuman's founder Steven Enamakel built the project after spending 3 hours setting up an open-source AI agent for his father — navigating API keys, YAML configs, and documentation — and concluding that "every powerful AI agent today is built for the 0.01% who can spin up their own runtime." 4 The result is a local-first desktop agent with a persistent memory tree built from the user's own data sources.
Stack and approach: Rust (62.1%) + TypeScript (34%) + React 19, packaged as a Tauri v2 native desktop app (not Electron) for macOS, Windows, and Linux. The core architecture is a Memory Tree: source adapters ingest data → canonicalize → chunk → store in SQLite plus an optional Obsidian vault. The tree auto-syncs on a 20-minute tick. A TokenJuice compression layer claims up to 80% context cost reduction; an independent review by PrimeAIcenter measured approximately 70% in a 5-day test. 5 118+ third-party integrations via OAuth (Composio). Only Gmail, Notion, and Slack currently provide full auto-ingest into the Memory Tree; other integrations are proxied tool calls. 4
Differentiation: Tauri v2 instead of Electron keeps idle memory low. The v0.54.0 release (May 19, 2026) ships fully local speech-to-text and text-to-speech via Whisper and Piper, a desktop mascot that can join Google Meet as a real participant with lip-synced TTS, and a dedicated crypto agent. 6 The GPL-3.0 license and piped-shell installer drew a TechTimes security flag — the OAuth aggregation across email, calendar, and payments represents a wide blast radius if the install chain is compromised. No independent security audit exists as of this week. 7
Verdict: Conditional ⭐. The Memory Tree architecture is the most thoughtful local agent memory design in this week's batch. Beta-stage execution with sync failures reported. Star it to watch the trajectory; hold for any production or privacy-sensitive use until the GPL + supply-chain concerns are resolved.
#3 · Imbad0202/academic-research-skills — 20,600 stars · +11,401 this week
Problem solved: AI-assisted academic writing today typically means "use ChatGPT to write the paper" — which produces hallucinations, fabricated citations, and work that doesn't represent the researcher's actual thinking. This Claude Code plugin takes the opposite position: 45 specialized agents handle the structural grunt work (citation verification, logical consistency checking, peer review simulation) while the human researcher remains responsible for the intellectual content. 8
Stack and approach: Installed as a Claude Code plugin (
/plugin marketplace add Imbad0202/academic-research-skills). Created by Cheng-I Wu (吳政宜). The 4 core skills orchestrate 45+ agents through an 8-stage pipeline: Stage 1 Research → Stage 2 Write → Stage 2.5 Integrity Gate → Stage 3 Peer Review → Stage 4 Revise → Stage 4.5 Final Integrity Gate → Stage 5 Finalize → Stage 6 Process Summary. v3.8 adds an opt-in claim audit pass (ARS_CLAIM_AUDIT=1) that fetches cited sources and verifies whether claims are actually supported — motivated by a Zhao et al. (2026) finding of 146,932 hallucinated citations in academic preprints during 2025 alone. 8 Full pipeline estimated cost: approximately $4–6 per 15,000-word paper.Differentiation: The peer review simulation uses an EIC role plus 3 dynamic reviewers plus a Devil's Advocate with a concession threshold protocol — structured to surface weaknesses rather than just confirm quality. Wu's stated design premise: "AI is your copilot, not the pilot." 8 The Hacker News post was flagged (82 points, comments not publicly accessible), suggesting a contested reception in the developer community — the specific objections remain unclear. License is CC-BY-NC 4.0, meaning commercial use is prohibited.
Verdict: ⭐ Star it if you write academic papers. The integrity gates and claim audit distinguish this from generic writing assistants. The HN controversy and non-commercial license narrow the addressable audience but don't undermine the tool's design quality.
#4 · obra/superpowers — 205,000 stars · +10,171 this week
Problem solved: AI coding agents default to rushing straight to implementation — skipping requirements clarification, picking libraries without asking, and producing code that compiles but misses the actual goal. Superpowers is a set of SKILL.md files created by Jesse Vincent (creator of Request Tracker, co-founder of Keyboardio) that inject mandatory behavioral instructions at session start, enforcing a structured workflow before the agent writes a single line of code. 9
Stack and approach: Shell (66.4%) + JavaScript (24.8%). 7 supported platforms: Claude Code, Codex CLI/App, Factory Droid, Gemini CLI, OpenCode, Cursor, GitHub Copilot CLI. Install via
npx superpowers install or the official Anthropic plugin marketplace. The core workflow is sequential: brainstorm → plan (git worktrees) → write plan → execute or subagent-driven development → TDD → request code review → finish branch. A meta-skill (writing-skills) lets Claude create new skills following the same pattern. 9Differentiation: With 205,000 stars accumulated over 8 months (launched October 2025), this is the most widely adopted agent skills framework currently available, listed as the #1 Claude Code plugin. 10 The v5.1.0 release (May 4, 2026) removed legacy slash commands and introduced AI contributor guidelines after observing a 94% PR rejection rate from AI-generated contributions. 11 Vincent's design observation: Cialdini's persuasion principles (authority, commitment, reciprocity, social proof) work on LLMs, and Superpowers uses them to make agents more reliable rather than to break constraints. The SKILL.md instruction text itself is explicit: "IF A SKILL APPLIES TO YOUR TASK, YOU DO NOT HAVE A CHOICE. YOU MUST USE IT." 10
Verdict: ⭐ Star it. Eight months of real-world validation and 205K stars across multiple agent platforms make this the lowest-risk place to start with agent skills frameworks. If you use only one repo from this list, make it this one.
#5 · Lum1104/Understand-Anything — 25,900 stars · +9,102 this week
Problem solved: Code knowledge graphs that show complexity don't help developers understand a codebase — they just visualize how tangled it is. Understand-Anything's stated goal is "graphs that teach > graphs that impress." 12 The tool generates an interactive web dashboard — not just an MCP server — with force-directed graph visualization, guided tours, persona-adaptive UI, and diff impact analysis, aimed at developers exploring unfamiliar repos.
Stack and approach: TypeScript (70.6%) + JavaScript (15.5%) + Python (9.7%) + Astro (2.7%). Hybrid architecture: tree-sitter handles deterministic structural parsing; an LLM layer adds plain-English summaries, architectural layer assignments (presentation / business / data / infrastructure), and business domain analysis. The multi-agent pipeline runs 7 specialized agents: project-scanner, file-analyzer, architecture-analyzer, tour-builder, graph-reviewer, domain-analyzer, and article-analyzer. Output is a JSON knowledge graph committed to
.understand-anything/knowledge-graph.json — a team artifact that can live in the repo. Supports 10+ agent platforms including Copilot, Gemini CLI, KIMI CLI, Cline, and Antigravity. Launched on Product Hunt May 19, 2026, reaching v2.7.3. 13Differentiation: CodeGraph vs. Understand-Anything is the sharpest contrast of this week. Both use tree-sitter; both appeared on the same Trending page on May 23. The divergence: CodeGraph's primary consumer is the AI agent (pre-indexed SQLite, 9 MCP tools, zero UI, documented token savings). Understand-Anything's primary consumer is the human developer (interactive dashboard, guided tours, business domain mapping). 2 Understand-Anything has not published agent-efficiency benchmarks comparable to CodeGraph's 7-repo study — the README emphasizes features over quantitative claims. Community users have raised questions about whether repo-scoped knowledge graphs deliver real value versus "native grep+read for agents." 14
Verdict: ⭐ Star it for human-side codebase exploration. For agent token efficiency, CodeGraph is the better pick. For onboarding a new team member to a complex repo, Understand-Anything's guided tours and visual dashboard are the more useful primitive.

#6 · rohitg00/ai-engineering-from-scratch — 16,010 stars · +6,944 this week
Problem solved: Developers using AI tools professionally outnumber those who understand how to build them. The project's README cites a specific gap: 84% of students already use AI tools, but only 18% feel prepared to use them professionally. 15
Stack and approach: Created by Rohit Ghumare (also behind last week's agentmemory). Python (76.1%), JavaScript (16.2%), HTML (5.2%), Julia (0.7%). 435 lessons across 20 stages covering the full stack from linear algebra to autonomous agent swarms, totaling approximately 320 hours of content. The curriculum methodology is "Build It / Use It / Ship It" — each lesson produces one reusable artifact: a prompt, a skill, an agent, or an MCP server. Two built-in agent skills:
/find-your-level (a 10-question placement test that generates a personalized learning path) and /check-understanding (stage-completion quizzes). MIT License. 15Differentiation: PyShine's May 20 review described it as "the most comprehensive open-source AI curriculum available" for developers who want to understand AI from first principles rather than just use it. 16 The structural difference from fast.ai or Andrej Karpathy's zero-to-hero approach: every lesson produces a deployable artifact, not just an understanding of a concept. The practical constraint: 1,090 of the 1,115 commits come from a single maintainer — bus-factor risk is real for a 320-hour curriculum. 15
Verdict: ⭐ Star it if you're serious about building AI systems end-to-end. The build-first methodology and artifact-per-lesson design are sound. Don't mistake it for a quick course — 320 hours is a meaningful time commitment.
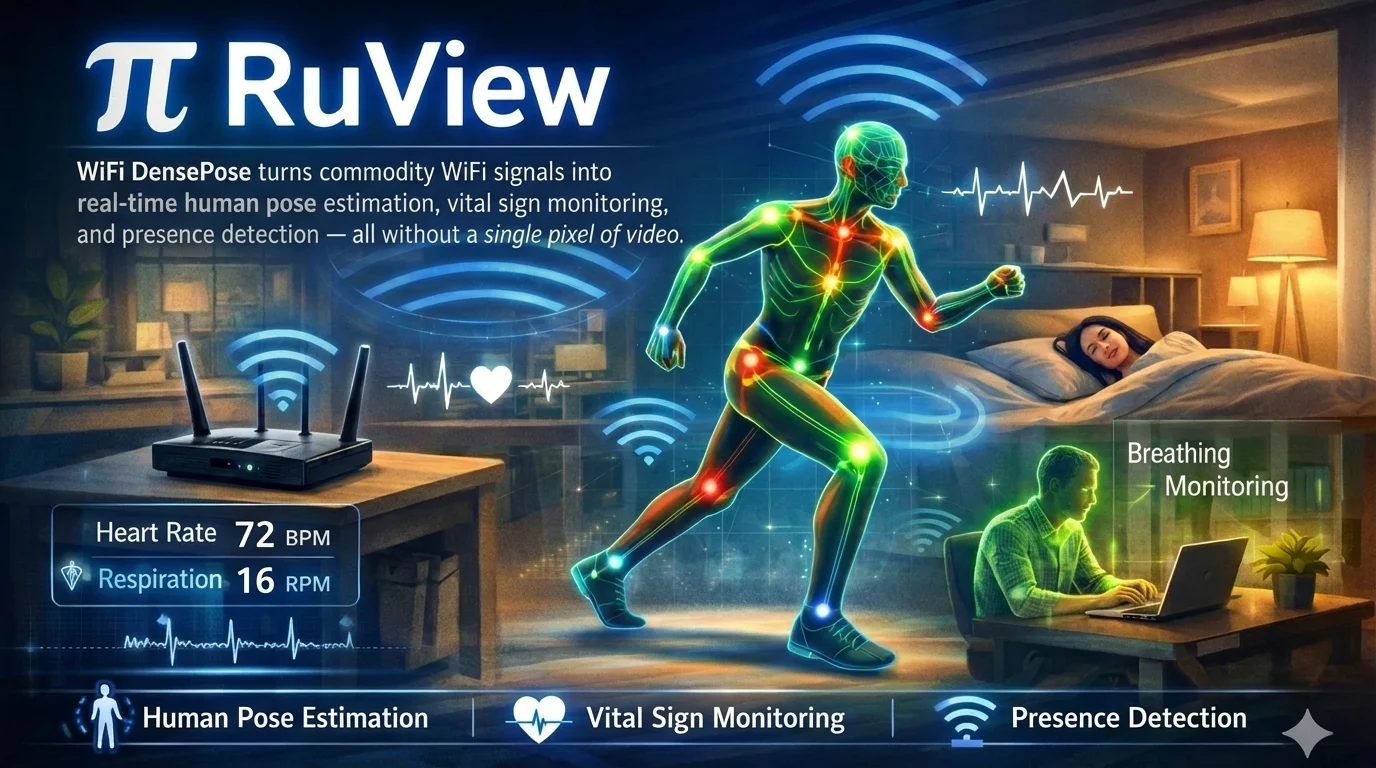
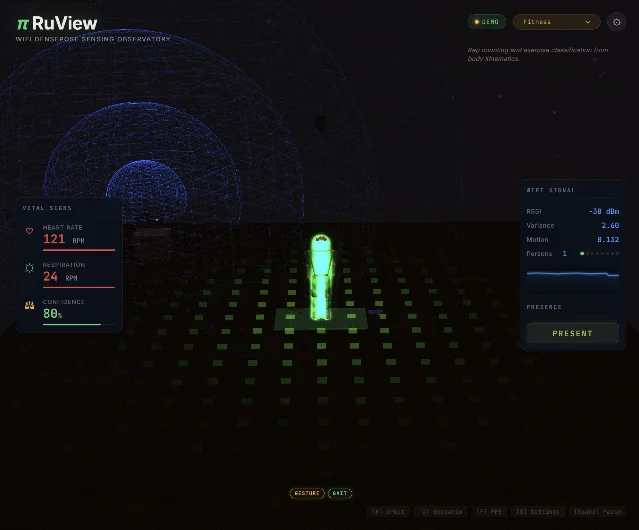
#7 · ruvnet/RuView — 65,413 stars · +6,461 this week
Problem solved: Detecting presence, movement, and vital signs in a space normally requires cameras — which raise privacy and installation concerns. RuView uses WiFi Channel State Information (CSI) captured from commodity ESP32-S3 hardware ($9 per node) to infer spatial activity without any camera. 17
Stack and approach: Rust, MIT License. The data pipeline runs ESP32-S3 mesh nodes that capture CSI → RuVector signal processing (Rust) → a 128-dimensional contrastive learning encoder (4-bit quantized, 8KB footprint) → 105 edge Cog modules covering health, safety, retail, and industrial applications. Claimed capabilities include presence detection, respiratory rate and heart rate monitoring, 17-keypoint pose estimation, and fall detection. A pretrained model (
ruvnet/wifi-densepose-pretrained) is available on Hugging Face with 12.2 million training steps and 60K frames of training data. 18 Multiple hardware configurations are supported: Docker simulation ($0), single ESP32-S3 node ($9), mesh setup ($54), full kit with Cognitum Seed ($140). Integration with Home Assistant via a single --mqtt flag; Matter Bridge support for Apple Home, Google Home, and Alexa. 17Differentiation: The core differentiator is user-controlled local processing — no cloud dependency, no subscription, data stays on-device. Knightli's independent assessment was measured: "RuView is worth watching, but it needs a cool head. It is not a finished monitoring system that can 'see through walls' as soon as you start a Docker container." 19 A Reddit commenter raised reproducibility questions about the 17-joint pose estimation accuracy claims, and a separate commenter suggested the project may have been partly AI-generated. The published benchmarks show 100% validation accuracy for binary presence detection; the pose estimation claims at range have not been independently verified. 17
Verdict: Conditional ⭐. Star it for research and prototyping on presence detection and vital sign monitoring. Treat the advanced pose estimation claims as aspirational until independently reproduced. The $9 hardware entry point makes it cheap to test.
#8 · HKUDS/CLI-Anything — 40,061 stars · +4,759 this week
Problem solved: Most existing software was designed for human users, not AI agents. CLI-Anything, from the Hong Kong University Data Intelligence Lab (HKUDS), automates converting any software into an agent-operable tool: a 7-stage pipeline analyzes the target software's codebase, generates a CLI harness, writes a SKILL.md agent skill definition, produces unit tests and end-to-end tests, and publishes to PyPI. 20
Stack and approach: 688 commits, Apache 2.0 License. Latest release v0.3.0 (April 24, 2026). The test suite covers 2,330 cases (1,732 unit tests + 579 end-to-end + 19 Node.js) with 100% pass rate at the time of release. A community registry, CLI-Hub (
clianything.cc), lets developers browse, search, and install community-built CLI harnesses via pip install cli-anything-hub. Recent additions to the Hub include harnesses for Rekordbox DJ software, Calibre e-book management, 3MF 3D printing mesh, and MiniMax AI. 21Differentiation: The scale of the automation is the key differentiator — not hand-writing an MCP server, but generating the full integration layer. The security dimension is the main concern: VentureBeat's May 5 investigation found that SKILL.md files can be poisoned, and Snyk research cited in the same piece identified security issues in 13.4% of agent skills packages. Merritt Baer (Enkrypt AI CSO, former AWS deputy CISO) stated the problem concisely: "SAST and SCA were built for code and dependencies. They don't inspect instructions." 22 VentureBeat's framing: "CLI-Anything is not the threat. It is the proof case that the agent integration layer exists, that it is growing fast, and that the attacker community has already found it." 22
Verdict: Conditional ⭐. Star it as a productivity multiplier for adding agent-native interfaces to existing software. Treat any SKILL.md file from CLI-Hub as untrusted input — read it before using it, the same way you'd read a shell script before running it.
#9 · supertone-inc/supertonic — 10,173 stars · +2,726 this week
Problem solved: Existing open-source text-to-speech systems are either large (0.7B–2B parameters, requiring GPU inference) or small but poor quality. Supertonic 3, from Korean AI voice company Supertone Inc. (clients include Netflix, Disney, and HYBE), fits 31-language multilingual TTS into 99 million parameters running fast enough for real-time on-device use. 23
Stack and approach: Architecture: speech autoencoder → latent flow-matching text-to-latent mapping → ConvNeXt blocks → ONNX Runtime for cross-platform inference. Backed by a peer-reviewed paper (Kim et al., arXiv:2503.23108). 24 Performance figures: M4 Pro CPU reaches 1,263 characters/second (real-time factor 0.012x — 83× faster than real time); RTX 4090 reaches 12,164 characters/second; Raspberry Pi achieves RTF 0.3x (3.3× faster than real time). 23 The Python SDK v1.3.1 (May 18, 2026) added
supertonic serve, exposing a local HTTP server with an OpenAI-compatible /v1/audio/speech endpoint. 25 MIT license (model uses OpenRAIL-M). 12 community integrations exist including a Transformers.js WebGPU implementation and Pinokio one-click deploy.Differentiation: The natural-language number handling is a practical edge: Supertonic correctly reads financial expressions like "$5.2M," phone numbers, and technical units without preprocessing. ElevenLabs, OpenAI, and Gemini TTS all fail on these cases according to the project's own testing — an independent third-party comparison on this specific dimension hasn't been published. The community friction point: voice cloning requires uploading audio to Supertone's paid online service, reported at approximately $50 per voice clone on Reddit discussion threads. 26 One commenter's summary of the sentiment: "They gated the best part." Chinese language support is absent (issues #147 and #153 are open requests). 23 Android output has been reported as corrupted audio for at least one user.
Verdict: ⭐ Star it for on-device TTS integration. For any project requiring edge inference — browser extensions, e-readers, IoT, offline mobile apps — 99M parameters at RTF 0.012 is a real capability step. The voice cloning paywall is a deliberate product choice, not a technical limitation.

#10 · can1357/oh-my-pi — 7,053 stars · +2,361 this week
Problem solved: The standard diagnosis when an AI coding agent produces wrong edits is "the model isn't capable enough." Can Bölük (security researcher, can1357) argues the actual problem is usually the harness — the tool layer that controls how the model receives input and expresses output. oh-my-pi is a fork of the Pi terminal coding agent that systematically reworks that layer. 27
Stack and approach: TypeScript (81.2%) + Rust (10.0%, approximately 27,000 lines of core), running on Bun (≥1.3.14). Supports 40+ LLM providers, 32 built-in tools, 13 LSP operations (semantic rename, go-to-definition, find-references), and 27 DAP operations (debugger attach, breakpoints, step-through). Integrates natively with lldb, dlv, and debugpy. Persistent Python and JavaScript execution environments retain state across tool calls. arXiv PDFs can be read in structured form. GitHub PR/Issue content is accessible as filesystem paths. 27
Differentiation: The headline innovation is Hashline: each source line gets a 2–3 character content hash as an anchor, so the model references hash tokens instead of retyping surrounding context when making edits. Bölük's benchmark (16 models × 3 edit formats × 540 runs) found Grok Code Fast 1's edit success rate jumped from 6.7% to 68.3% with Hashline enabled, and Grok 4 Fast output tokens dropped by 61%. 28 "The harness problem is real, measurable, and it's the highest-leverage place to innovate right now," Bölük wrote in February 2026. 28 Knightli's review noted the more interesting aspect is structural: "oh-my-pi reorganizes the tool layer that often holds AI coding back" — integrating file read, search, edit, LSP, debugger, browser, and sub-agent dispatch into one coherent workflow rather than treating them as separate integrations. 29
Verdict: ⭐ Star it if you care about the harness layer. The Hashline benchmark is specific and reproducible. The combination of LSP + debugger + sub-agent dispatch in a single harness is the part worth extracting — the design thinking here applies to any agentic coding tool, not just Pi.
Three patterns worth extracting
The agent skills primitive is becoming domain-specific. Three weeks ago, SKILL.md files meant coding workflows. This week, the same pattern covers academic research (ARS's 45-agent pipeline), scientific tooling (not in this week's top 10 but trending alongside), and general software integration (CLI-Anything's auto-generated SKILL.md harnesses). What started as a personal productivity pattern for Jesse Vincent in October 2025 is now showing up as the default structured-instruction format for multi-agent systems. The reusable insight: a skill file is just a typed behavioral contract between a human and an agent — and you can write one for any domain-specific workflow.
Pre-indexed code intelligence is a distinct infrastructure category. CodeGraph and Understand-Anything appearing simultaneously on the same Trending page is the market making this call. Both use tree-sitter as the deterministic parsing layer; both build queryable representations on top. The split after that is meaningful: CodeGraph routes all queries through an MCP server for agent consumption; Understand-Anything routes through a web dashboard for human consumption. These aren't competing implementations of the same thing — they're two different consumers of the same underlying primitive. The design question for any team building agent infrastructure: which consumers do you have?
The harness matters more than the model for edit accuracy. oh-my-pi's Hashline result — taking Grok Code Fast 1 from 6.7% to 68.3% edit success rate with no model change — is the clearest data point this week on where optimization leverage lives. The underlying principle: models aren't bad at coding; they're bad at expressing their intent through the specific tool call formats they've been given. Changing the representation (line anchors instead of full-context rewrites) changes the success rate by a factor of 10. This finding has direct implications for any custom agent harness: before swapping the model, measure whether the tool format is the actual bottleneck.
Cover image: GitHub: ruvnet/RuView — WiFi spatial sensing hardware poster
참고 출처
- 1GitHub: colbymchenry/codegraph
- 2AgentConn: CodeGraph analysis
- 3Towards AI: Shubham Choudhary review
- 4GitHub: tinyhumansai/openhuman
- 5PrimeAIcenter: OpenHuman Review
- 6GitHub: openhuman releases
- 7AlphaSignal: How OpenHuman works
- 8GitHub: Imbad0202/academic-research-skills
- 9GitHub: obra/superpowers
- 10Verdent: What is Superpowers?
- 11Jesse Vincent blog: Superpowers launch
- 12GitHub: Lum1104/Understand-Anything
- 13GitHub: Lum1104/Understand-Anything releases
- 14Hacker News: Understand Anything
- 15GitHub: rohitg00/ai-engineering-from-scratch
- 16PyShine: AI Engineering from Scratch review
- 17GitHub: ruvnet/RuView
- 18Hugging Face: ruvnet/wifi-densepose-pretrained
- 19Knightli: RuView review
- 20GitHub: HKUDS/CLI-Anything
- 21CLI-Anything Hub
- 22VentureBeat: CLI-Anything security
- 23GitHub: supertone-inc/supertonic
- 24arXiv: SupertonicTTS
- 25Hugging Face: Supertone/supertonic-3
- 26Reddit: Supertonic community discussion
- 27GitHub: can1357/oh-my-pi
- 28Can Bölük blog: The harness problem
- 29Knightli: oh-my-pi review
이 콘텐츠를 둘러싼 관점이나 맥락을 계속 보강해 보세요.